class VacuumCleanerAgent:
def __init__(self):
self.position = (0, 0) # Starting position
self.environment = [[0, 0, 1], [0, 1, 0], [0, 0, 0]] # 0 is clean, 1 is dirty
def perceive(self):
x, y = self.position
return self.environment[x][y]
def decide(self, percept):
if percept == 1:
return 'suck'
else:
return 'move'
def act(self, action):
if action == 'suck':
x, y = self.position
self.environment[x][y] = 0 # Clean the dirt
elif action == 'move':
x, y = self.position
if y + 1 < len(self.environment[0]):
self.position = (x, y + 1) # Move right
elif x + 1 < len(self.environment):
self.position = (x + 1, 0) # Move down and reset to the first column
def run(self):
while True:
percept = self.perceive()
action = self.decide(percept)
self.act(action)
if self.position == (len(self.environment) - 1, len(self.environment[0]) - 1):
break
agent = VacuumCleanerAgent()
agent.run()Agents
Introduction to AI Agents
What is an AI Agent?
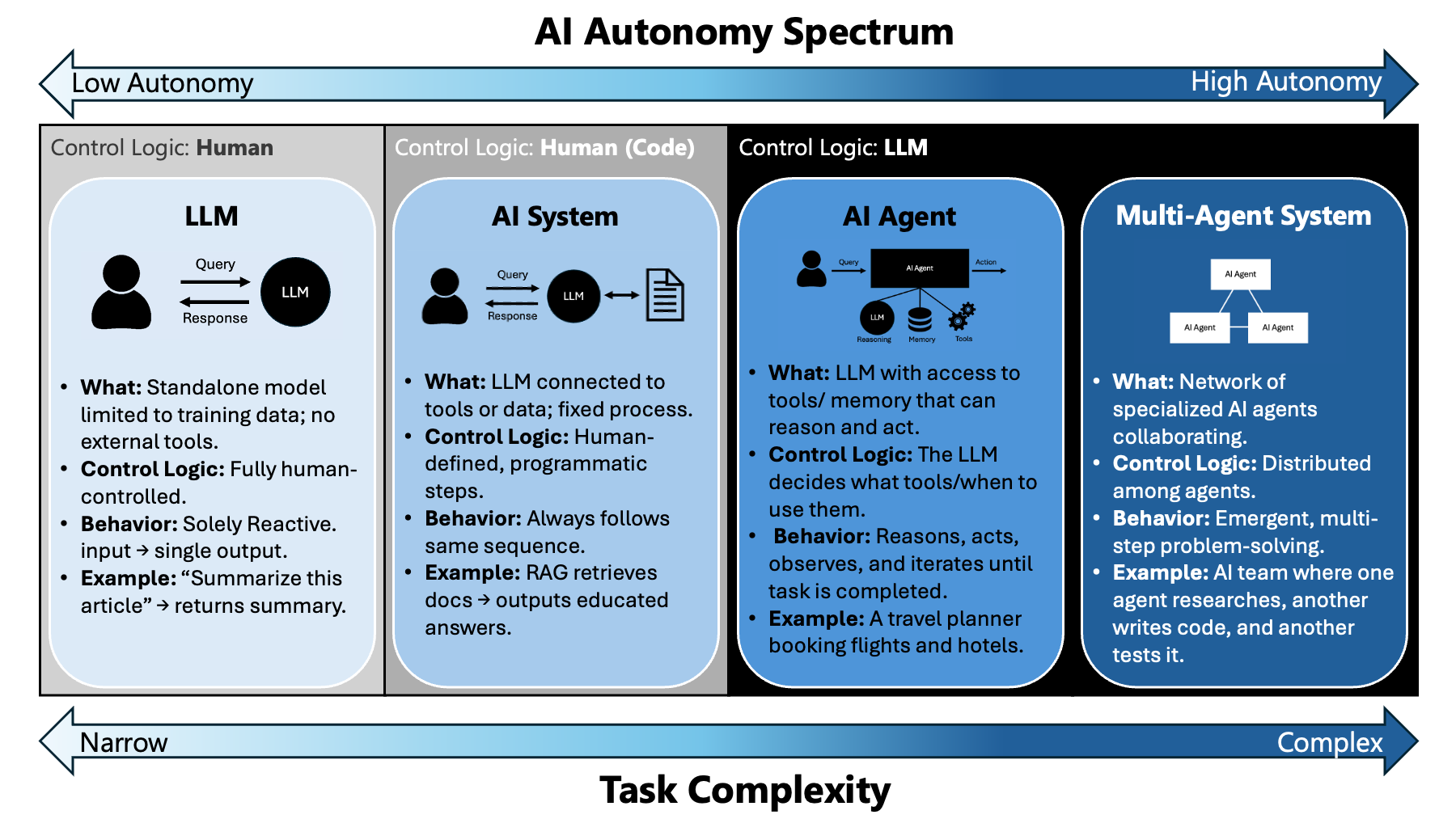
To understand what an AI agent is, it helps to first build context around the systems we have studied so far. One way to compare them is by looking at their control logic—the set of rules or instructions that determine how a system operates step by step.
We began with Large Language Models (LLMs). These are powerful tools for tasks like summarizing an article or drafting an email. In this case, the control logic resides entirely with the human. The user provides a prompt, the model generates a response, and the human decides how to interpret or use that output. While useful, LLMs have a clear limitation: they are bound by their training data and cannot access new information on their own.
To overcome this, we explored Retrieval-Augmented Generation (RAG). RAG extends an LLM by connecting it to external sources such as a database or search engine. This makes the system far more useful, since it can pull in relevant information at runtime. However, the control logic is still defined by humans. The system always follows the same programmatic sequence: retrieve documents, feed them into the LLM, and return a response. No matter the situation, the path is fixed.
AI agents represent the next stage. Instead of following a rigid script, an agent allows the control logic to live inside the LLM itself. In this setup, the model becomes the brain of the system. It can break a problem into smaller steps, decide which tools to use, take actions, observe results, and adapt its strategy until it reaches a solution. This autonomy shifts the role of the model from a passive component to an active problem-solver.
At the highest level of autonomy, we encounter multi-agent systems. These environments consist of multiple LLM-powered agents that coordinate with each other to tackle complex, multi-step tasks. For example, one agent might specialize in retrieving data, another in analysis, and another in writing a final report. In this case, the control logic is distributed across multiple agents, enabling collaboration and division of labor.
Taken together, these stages form a spectrum of autonomy:
- LLMs — control logic resides in the human
- RAG — control logic is fixed and human-defined
- Agents — control logic moves inside the LLM
- Multi-agent systems — control logic is distributed across agents
The diagram below illustrates this progression, showing how both autonomy and task complexity increase as control shifts from human-defined workflows to LLM-driven decision-making.
A Short History of AI Agents
The idea of an AI agent is not new. In the classical AI framework, most famously described in Russell & Norvig’s Artificial Intelligence: A Modern Approach, an agent is defined as anything that:
- Perceives its environment through sensors
- Acts on the environment through actuators
- Uses a decision-making function to map perceptions to actions in pursuit of goals
For example, a robot might use a camera (sensor) to see, wheels (actuators) to move, and a decision algorithm to navigate a maze.
Modern AI agents, built on LLMs, reinterpret this framework in a digital context:
- Environment → the digital world where the agent operates (APIs, databases, the internet, conversation history)
- Sensors → inputs such as user prompts, retrieved documents, or API outputs
- Actuators → outward actions like tool calls, database updates, or generated responses
The big shift is in the decision-making function. In classical agents, this logic was hand-coded. In modern agents, the LLM itself provides the control logic—planning, adapting, and deciding what to do next. This marks a leap from scripted behavior to flexible, language-driven autonomy.
Why Agents Matter
At first glance, an AI agent might seem like just an upgraded version of RAG. But the real difference lies in autonomy. Whereas RAG follows a fixed, human-defined sequence of steps, an agent can dynamically decide what to do next based on the situation. This ability makes agents especially valuable for open-ended, multi-step problems where the path to a solution is not obvious in advance.
Think about booking travel. It is rarely a one-shot task. You might search for flights, compare options, adjust your dates, check hotel availability, and then revise everything when you see a better deal. Or consider managing a business workflow: pulling data from a database, analyzing it, drafting a report, sending an email, and waiting for a response before continuing. A research assistant faces the same challenge: exploring multiple sources, synthesizing information, identifying gaps, and refining the search until the picture is complete.
These are all problems where autonomy matters. A traditional system like RAG can only run through a predefined sequence, but an agent can adapt, plan, and act on its own—reducing the need for humans to micromanage each step. In practice, this makes agents far more capable partners for tasks that involve uncertainty, iteration, and complex decision-making.
Core Capabilities of AI Agents
The defining capability of an AI agent is multistep reasoning. Unlike a simple LLM call, which generates an answer in one pass, multistep reasoning allows the system to approach a goal through a sequence of intermediate steps: decide what to do, take an action, observe the result, and update its plan. This stepwise loop is what enables agents to handle tasks that are too complex for a single response.
Supporting this core loop are several key capabilities:
- Planning – the ability to decompose a high-level objective into smaller actions, and to update that plan as new information arrives.
- Tool use – the capacity to call external functions (APIs, databases, search engines, calculators) and incorporate their results.
- Memory – mechanisms for tracking context:
- Short-term memory keeps progress within a task (which steps have been completed).
- Long-term memory retains knowledge across sessions (facts, preferences, prior outputs).
- Short-term memory keeps progress within a task (which steps have been completed).
- Reflection and iteration – the ability to evaluate whether the current approach is working, recognize errors or dead ends, and adapt the strategy.
Summary: What is an AI Agent?
An AI agent is a software system that can make decisions and take actions to achieve specific goals.
Agents are made possible by placing an LLM in charge of the control logic—deciding which steps to take and in what order.
Chain-of-thought reasoning is an LLM capability that enables step-by-step thinking.
When combined with tools (to act in the environment) and memory (to track state across steps), this reasoning extends into multistep reasoning—allowing the agent to solve complex problems and carry out sophisticated tasks.
Limitations and Challenges of Agents
While AI agents represent a major step forward, they are far from flawless. Understanding their limitations is essential for using them responsibly and setting realistic expectations.
Reliability
Agents can be unpredictable. The same prompt may lead to different sequences of actions, and small variations in context can cause the agent to take a completely different path. This variability makes them difficult to depend on for mission-critical tasks without safeguards.Hallucination
Like all LLMs, agents can generate plausible but incorrect information. When combined with tool use, hallucinations can be amplified—for example, issuing invalid API calls or misinterpreting retrieved results.Cost and efficiency
Multistep reasoning often requires multiple tool calls, repeated planning, and re-tries. Each step consumes compute resources, API credits, or time, making agents far more expensive than one-shot LLM calls. Many tasks are better off using a simple LLM or AI System. If the task is simple (e.g., answering a factual question or drafting a short email), an agent may loop through unnecessary steps, slowing down the process and wasting resources.Safety and control
Giving an agent too much autonomy can be risky. Without constraints, an agent might take unwanted actions, misuse tools, or enter infinite loops. For this reason, most production systems today are “agentic but constrained”: they limit tool access, enforce strict rules, and often keep a human in the loop.Evaluation difficulty
Measuring agent performance is challenging. Unlike classification models where accuracy is clear-cut, success for agents depends on context: Did it achieve the goal? Did it do so efficiently? Was the reasoning safe and interpretable? These questions are harder to answer systematically.
In practice, these challenges mean that agents are often deployed in narrow, well-defined domains with strong guardrails, rather than as fully autonomous general-purpose systems. This balance allows developers to harness their power while maintaining safety, cost control, and reliability.
Building AI Agents
Agent Architecture
At the heart of every AI agent is a decision-making loop that allows it to operate autonomously. This loop can be described as Reason → Act → Observe → Update, with memory supporting each stage.
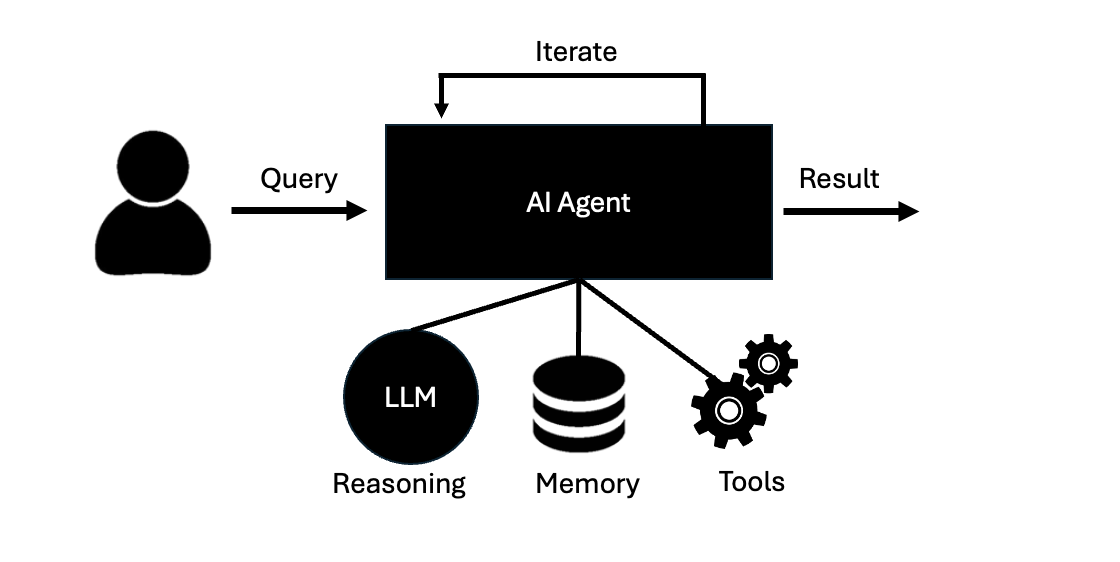
- Reason – The agent decides what to do next. This is powered by the LLM’s ability to use chain-of-thought reasoning: breaking down the problem, planning a step, and generating an action.
- Act – The agent executes the step, often by calling an external tool such as a database, API, calculator, or search engine.
- Observe – The agent takes in the result of its action. For example, it might read the output of an API call or the contents of a retrieved document.
- Update – Based on the observation, the agent revises its plan. It may confirm progress, identify errors, or decide on the next action.
Throughout this loop, memory plays a critical role:
- Short-term memory retains the immediate context of the current task, such as prior steps, intermediate results, and the agent’s reasoning scratchpad.
- Long-term memory allows the agent to carry knowledge, facts, or user preferences across multiple sessions or tasks.
Without memory, the agent could still reason, act, and observe—but it would forget prior steps and lack continuity. With memory, the agent can perform true multistep reasoning, keeping track of where it is in the loop and adapting as the task unfolds.
In practice:
- In a coded framework (e.g., LangChain), this loop is implemented through function calls and state management.
- In a no-code platform (e.g., Make or n8n), the loop maps to nodes, flows, and conditional branches—each representing a piece of the cycle.
✅ Takeaway: The agent architecture is simple but powerful. By looping through Reason → Act → Observe → Update, and anchoring that process with memory, an AI agent transforms from a one-shot LLM into an adaptive system capable of solving complex, multi-step tasks.
In the realm of artificial intelligence, agents are entities that perceive their environment through sensors and act upon that environment using actuators. These agents can range from simple rule-based systems to complex learning algorithms capable of adapting to new situations. The concept of an AI agent is foundational in AI system design and is crucial for developing workflows that involve multi-step reasoning. An AI agent operates autonomously to achieve specific goals by making decisions based on its perceptions and the knowledge it possesses.
The behavior of an AI agent is determined by its ‘agent function,’ which maps any given percept sequence (the history of perceptions) to an action. This function can be implemented in various ways, from simple condition-action rules to sophisticated algorithms that involve learning and adaptation. A key aspect of designing AI agents is ensuring that they can handle the complexity of real-world environments, which often requires them to perform multi-step reasoning and adapt to changes over time.
To illustrate the concept of AI agents, consider a simple example of a vacuum cleaner robot. This robot is an agent that perceives its environment (a room) through sensors that detect dirt and obstacles. Based on its perceptions, the robot decides on actions such as moving forward, turning, or vacuuming. The agent’s goal is to clean the room efficiently. This example highlights the basic structure of an agent: perception, decision-making, and action, all directed towards achieving a goal.
In the Python code example above, we define a simple VacuumCleanerAgent class. The agent has a basic environment represented as a grid, where ‘1’ indicates a dirty spot and ‘0’ indicates a clean spot. The agent’s behavior is determined by its decision-making process, which in this case is a straightforward rule: if it perceives dirt, it performs the ‘suck’ action to clean it; otherwise, it moves to the next position. This simple agent demonstrates the core components of an AI agent: perception, decision-making, and action.
This foundational understanding of AI agents sets the stage for developing more sophisticated systems capable of multi-step reasoning. As we move forward, we will explore how agents can be designed to handle more complex tasks, adapt to new information, and optimize their actions to achieve long-term goals. Such capabilities are essential for building strategic AI solutions that can operate effectively in dynamic environments.
Understanding Multi-Step Reasoning
Multi-step reasoning is a fundamental capability in constructing AI agents that can perform complex tasks. Unlike simple decision-making processes, multi-step reasoning involves breaking down a problem into a series of interconnected steps, each requiring its own logic and decision-making. This approach is crucial in scenarios where decisions are dependent on the outcomes of previous steps, and where the agent must navigate through a sequence of actions to achieve a desired goal.
In multi-step reasoning, the AI agent needs to maintain a state or context that evolves as it processes each step. This context allows the agent to track its progress and adjust its strategy as necessary. For instance, consider a customer service chatbot that needs to authenticate a user, understand their issue, and provide relevant solutions. Each of these tasks represents a step in the reasoning process, requiring the agent to gather information, make decisions, and execute actions based on the accumulated context.
To illustrate this concept, let’s consider an example of a simple AI agent designed to solve a maze. The agent’s goal is to find the exit, starting from a given point. The maze-solving task can be broken down into several steps: exploring the maze, marking visited paths, backtracking when necessary, and recognizing the exit. The agent must reason through these steps, adapting its path based on the structure of the maze and its current position.
class MazeSolver:
def __init__(self, maze):
self.maze = maze
self.start = self.find_start()
self.path = [] # to keep track of the path taken
def find_start(self):
# Locate the starting point in the maze
for i, row in enumerate(self.maze):
for j, value in enumerate(row):
if value == 'S': # 'S' marks the start
return (i, j)
return None
def solve(self):
# Begin solving the maze from the start position
return self.explore(self.start[0], self.start[1])
def explore(self, x, y):
# Check if current position is the exit
if self.maze[x][y] == 'E': # 'E' marks the exit
return True
# Mark the current cell as visited
self.maze[x][y] = 'V'
self.path.append((x, y))
# Explore neighbors (up, down, left, right)
for dx, dy in [(-1, 0), (1, 0), (0, -1), (0, 1)]:
nx, ny = x + dx, y + dy
if self.is_valid(nx, ny):
if self.explore(nx, ny):
return True
# Backtrack if no path is found
self.path.pop()
return False
def is_valid(self, x, y):
# Check if the position is within bounds and not visited
return (0 <= x < len(self.maze) and
0 <= y < len(self.maze[0]) and
self.maze[x][y] in (' ', 'E'))
# Example maze
maze = [
['S', ' ', ' ', '#', ' ', ' ', ' '],
['#', '#', ' ', '#', ' ', '#', ' '],
[' ', ' ', ' ', ' ', ' ', ' ', ' '],
[' ', '#', '#', '#', '#', '#', ' '],
[' ', ' ', ' ', ' ', ' ', ' ', 'E']
]
solver = MazeSolver(maze)
if solver.solve():
print("Path to exit found:", solver.path)
else:
print("No path to exit found.")In the code example above, the MazeSolver class implements a simple depth-first search algorithm to navigate through the maze. The agent begins at the start position, marked by ‘S’, and attempts to find the exit, marked by ‘E’. It explores each path recursively, marking visited cells to avoid revisiting them, and backtracks when it encounters dead ends. This process exemplifies multi-step reasoning as the agent systematically breaks down the task of solving the maze into manageable steps, dynamically adjusting its path based on the information gathered during exploration.
This example highlights the importance of maintaining state and context in multi-step reasoning. The agent’s path and the maze’s current state (with visited cells marked) are crucial for making informed decisions at each step. Moreover, this approach can be extended to more complex environments and tasks, where the agent might need to handle multiple objectives, constraints, and dynamic changes in the environment. Understanding and implementing multi-step reasoning is key to building strategic AI solutions that can tackle real-world challenges with efficiency and adaptability.
The Role of Agents in AI Workflows
In the context of artificial intelligence, agents play a crucial role in executing workflows that require multi-step reasoning. An agent, in this sense, can be thought of as an autonomous entity that perceives its environment through sensors and acts upon that environment using actuators. In AI workflows, agents are typically software programs that can make decisions and carry out tasks to achieve specific goals. These agents can be simple rule-based systems or sophisticated entities capable of learning and adapting over time.
The primary function of agents in AI workflows is to manage the complexity inherent in multi-step reasoning tasks. This involves breaking down a complex problem into smaller, manageable sub-tasks, and then executing these tasks in a coordinated manner. For instance, consider an AI system designed to manage an e-commerce platform. Such a system might use agents to handle inventory management, customer interactions, and payment processing. Each of these tasks involves multiple steps that require reasoning and decision-making.
Agents can be categorized based on their level of sophistication and autonomy. Reactive agents operate based on a set of predefined rules and respond to changes in the environment without any memory of past interactions. On the other hand, deliberative agents are capable of planning and have a model of the world that allows them to predict the outcomes of their actions. Hybrid agents combine both reactive and deliberative approaches, allowing them to respond quickly to changes while also planning for future actions.
Let’s consider a practical example of an agent in a multi-step reasoning workflow: a customer service chatbot. This agent must understand customer queries, retrieve relevant information, and provide appropriate responses. The workflow involves several steps, such as natural language understanding, information retrieval, and response generation. Each of these steps requires the agent to reason about the task at hand and make decisions based on the input it receives.
class ChatbotAgent:
def __init__(self, knowledge_base):
self.knowledge_base = knowledge_base
def understand_query(self, query):
# Simulate understanding the query
print(f"Understanding query: {query}")
return query.lower().split()
def retrieve_information(self, keywords):
# Simulate retrieving information based on keywords
print(f"Retrieving information for: {keywords}")
return "Information about " + " ".join(keywords)
def generate_response(self, information):
# Simulate generating a response
print(f"Generating response.")
return f"Here is what I found: {information}"
def handle_customer_query(self, query):
# Complete workflow
keywords = self.understand_query(query)
information = self.retrieve_information(keywords)
response = self.generate_response(information)
return response
# Example usage
knowledge_base = {"ai": "Artificial Intelligence is the simulation of human intelligence in machines."}
chatbot = ChatbotAgent(knowledge_base)
response = chatbot.handle_customer_query("Tell me about AI")
print(response)In the code example above, we define a simple ChatbotAgent class that simulates a multi-step reasoning process. The agent first understands the query by breaking it down into keywords. It then retrieves information from a knowledge base using these keywords and finally generates a response based on the retrieved information. This workflow demonstrates how an agent can autonomously handle a task requiring several reasoning steps, each of which involves making decisions based on the current state of the environment.
Agents in AI workflows are not limited to chatbots. They can be used in a wide range of applications, from autonomous vehicles that navigate complex environments to financial systems that analyze market trends and make investment decisions. Regardless of the application, the core principle remains the same: agents are designed to autonomously execute tasks that require multi-step reasoning, thereby simplifying complex workflows and enhancing the overall efficiency of AI systems.
Overview of Model Context Protocol
In the context of building strategic AI solutions, particularly when developing agent workflows for multi-step reasoning, understanding the Model Context Protocol (MCP) is essential. MCP is a framework that allows AI systems to effectively manage and utilize the context needed for decision-making across multiple steps. By maintaining context, agents can make informed decisions that are consistent with previous interactions and adapt to new information as it becomes available.
The Model Context Protocol is designed to handle the complexities of real-world environments, where decisions are not made in isolation but rather as part of a sequence of actions. This involves maintaining a context that includes historical data, current state information, and potential future scenarios. By structuring this information effectively, agents can reason through multiple steps and adjust their strategies as needed.
A fundamental aspect of MCP is the ability to store and retrieve context information efficiently. This context can include the agent’s previous actions, the outcomes of those actions, and any external factors that may influence future decisions. By leveraging this stored context, agents can avoid redundant computations and make more accurate predictions about future states.
class ContextManager:
def __init__(self):
# Initialize an empty context list to store historical data
self.context = []
def add_to_context(self, data):
# Add new data to the context
self.context.append(data)
def get_context(self):
# Retrieve the current context
return self.context
# Example usage
context_manager = ContextManager()
context_manager.add_to_context({'step': 1, 'action': 'move', 'result': 'success'})
context_manager.add_to_context({'step': 2, 'action': 'pick', 'result': 'failure'})
# Retrieve context
print(context_manager.get_context())
# Output: [{'step': 1, 'action': 'move', 'result': 'success'}, {'step': 2, 'action': 'pick', 'result': 'failure'}]In the code example above, we define a simple ContextManager class that maintains a list of context entries. Each entry is a dictionary that records a step in the agent’s decision-making process, including the action taken and the result of that action. This structure allows the agent to retrieve and review its past actions to inform future decisions.
Another critical feature of MCP is the ability to update context dynamically. As the agent interacts with its environment, new information becomes available that might necessitate a change in strategy. The protocol must support the integration of this new data into the existing context seamlessly. This adaptability is crucial for agents operating in dynamic environments, where conditions can change rapidly and unpredictably.
def update_context(context_manager, new_data):
# Update the context with new data
context_manager.add_to_context(new_data)
# New data from the environment
new_data = {'step': 3, 'action': 'move', 'result': 'success'}
# Update the context
update_context(context_manager, new_data)
# Check updated context
print(context_manager.get_context())
# Output: [{'step': 1, 'action': 'move', 'result': 'success'}, {'step': 2, 'action': 'pick', 'result': 'failure'}, {'step': 3, 'action': 'move', 'result': 'success'}]In this updated code snippet, we demonstrate how new information can be added to the context using a helper function update_context. This function takes the current context manager and the new data as inputs, appending the new data to the context. This approach ensures that the agent’s decision-making process remains informed by the most recent and relevant information.
In summary, the Model Context Protocol is a vital component of AI agent workflows for multi-step reasoning. By effectively managing context, agents can make informed, adaptive decisions that reflect both historical data and new information. This capability is essential for building robust, strategic AI solutions that operate effectively in complex, real-world environments.
Designing Agent Workflows
In the context of building strategic AI solutions, designing agent workflows for multi-step reasoning is a crucial aspect. An agent workflow refers to a structured sequence of operations that an AI agent performs to achieve a specific task or a set of tasks. These workflows are essential in enabling AI systems to handle complex problems that require reasoning across multiple steps, often involving interactions with various data sources, models, and decision-making processes.
To develop effective agent workflows, it’s important to first understand the problem domain and the specific tasks that the agent needs to accomplish. This involves identifying the inputs, outputs, and constraints associated with each task. Once these elements are clearly defined, you can begin to design a workflow that systematically addresses the problem. A well-designed workflow should be modular, allowing for easy updates and maintenance, and should also be robust, capable of handling unexpected situations gracefully.
Let’s consider an example of an AI agent designed to assist in customer service. This agent needs to understand customer queries, retrieve relevant information, and provide accurate responses. The workflow for such an agent might involve the following steps: (1) Preprocessing the input to clean and standardize the data, (2) Utilizing natural language processing (NLP) techniques to interpret the query, (3) Accessing a knowledge base to extract relevant information, and (4) Generating a coherent response to the customer. Each of these steps can be thought of as a module within the overall workflow.
# Example of a simple agent workflow for a customer service chatbot
def preprocess_input(user_input):
# Step 1: Clean and standardize the input
return user_input.lower().strip()
def interpret_query(cleaned_input):
# Step 2: Use NLP to interpret the query
# For simplicity, we'll assume a simple keyword matching
if 'order status' in cleaned_input:
return 'order_status'
elif 'return policy' in cleaned_input:
return 'return_policy'
else:
return 'unknown'
def access_knowledge_base(intent):
# Step 3: Retrieve relevant information based on the interpreted intent
knowledge_base = {
'order_status': 'Your order is on the way and should arrive in 3-5 days.',
'return_policy': 'You can return any item within 30 days of purchase.'
}
return knowledge_base.get(intent, "I'm sorry, I don't have information on that.")
def generate_response(info):
# Step 4: Generate a response
return f"Response: {info}"
# Example usage
user_input = "Can you tell me about the return policy?"
cleaned_input = preprocess_input(user_input)
intent = interpret_query(cleaned_input)
info = access_knowledge_base(intent)
response = generate_response(info)
print(response) # Output: Response: You can return any item within 30 days of purchase.In this code example, we see a basic implementation of an agent workflow using a customer service chatbot. The workflow is divided into four distinct functions, each representing a step in the reasoning process. This modular approach not only makes the code more organized but also allows for flexibility in modifying or extending each part of the workflow as needed.
Another important aspect of designing agent workflows is handling errors and exceptions. In real-world applications, agents may encounter unexpected inputs or failures in external systems they rely on. Incorporating error handling mechanisms ensures that the agent can respond to such situations without crashing, maintaining a seamless user experience. For instance, in the above code, if the query is not recognized, the agent returns a default message indicating its inability to provide information.
# Adding error handling to the workflow
def access_knowledge_base_with_error_handling(intent):
# Step 3: Enhanced with error handling
knowledge_base = {
'order_status': 'Your order is on the way and should arrive in 3-5 days.',
'return_policy': 'You can return any item within 30 days of purchase.'
}
try:
return knowledge_base[intent]
except KeyError:
return "I'm sorry, I don't have information on that."
# Example usage with error handling
intent = 'unknown_intent'
info = access_knowledge_base_with_error_handling(intent)
response = generate_response(info)
print(response) # Output: Response: I'm sorry, I don't have information on that.In the revised function access_knowledge_base_with_error_handling, we’ve added a try-except block to handle cases where the intent is not found in the knowledge base. This prevents the program from crashing and allows it to gracefully inform the user that the requested information is unavailable. Such practices are vital in developing robust AI solutions that can operate reliably in diverse environments.
Implementing Control Flow in Agent Workflows
In the context of developing agent workflows, implementing control flow is a critical step that determines how an AI system processes information and makes decisions. Control flow refers to the order in which individual operations or instructions are executed within an agent’s workflow. In multi-step reasoning tasks, control flow ensures that the agent can handle complex sequences of operations, manage dependencies between tasks, and adapt to dynamic inputs or changing environments.
A well-designed control flow allows an AI agent to execute tasks conditionally, repeat tasks as needed, and handle exceptions gracefully. This is crucial in strategic AI solutions where decisions are often contingent on the outcomes of prior steps. For example, in a customer service chatbot, the control flow might dictate how the bot responds based on the user’s previous interactions, current mood, or specific queries. Implementing effective control flow involves using constructs such as conditionals, loops, and function calls, which can be orchestrated using programming languages like Python.
# Example of a simple control flow using conditionals and loops
def evaluate_customer_query(query):
if 'refund' in query:
return 'Process refund request.'
elif 'complaint' in query:
return 'Log complaint and escalate.'
else:
return 'Provide general information.'
queries = ['refund for order #1234', 'complaint about service', 'opening hours']
for query in queries:
response = evaluate_customer_query(query)
print(f"Query: {query} -> Response: {response}")In the above code, we demonstrate a basic control flow using a function evaluate_customer_query that processes customer queries. The function uses conditional statements (if, elif, and else) to decide the response based on the content of the query. A loop iterates over a list of queries, applying the function to each query and printing the response. This simple control flow structure allows the agent to make decisions based on the input it receives.
In more complex workflows, control flow might involve managing sequences of operations that depend on each other. Consider a scenario where an AI agent is responsible for processing an order. The agent must verify inventory, process payment, and finally, arrange shipping. Each of these steps is contingent upon the successful completion of the previous one. Here, control flow is essential to ensure that each step is executed in the correct order and that errors in any step are handled appropriately, possibly by retrying the operation or alerting a human operator.
# Example of control flow in a multi-step order processing
def process_order(order):
try:
if not verify_inventory(order):
raise Exception('Inventory check failed.')
if not process_payment(order):
raise Exception('Payment processing failed.')
arrange_shipping(order)
print('Order processed successfully.')
except Exception as e:
print(f'Error processing order: {e}')
# Dummy functions for illustration purposes
def verify_inventory(order):
# Assume inventory is always available
return True
def process_payment(order):
# Simulate a payment processing failure
return False
def arrange_shipping(order):
print('Shipping arranged.')
order = {'id': 1, 'items': ['item1', 'item2']}
process_order(order)In this example, the process_order function orchestrates a sequence of operations necessary to complete an order. Each step is encapsulated in its own function, and the main function uses control flow to manage these steps. If any step fails (as simulated by the process_payment function returning False), an exception is raised, and the error is caught and reported. This example highlights the importance of control flow in handling dependencies and ensuring robustness in agent workflows.
In summary, implementing control flow in agent workflows is essential for managing the execution of complex, multi-step reasoning tasks. By utilizing conditionals, loops, and exception handling, developers can create AI solutions that are not only effective but also resilient to the uncertainties and variabilities inherent in real-world applications. This foundational capability enables strategic AI solutions to operate autonomously and make informed decisions, ultimately enhancing their utility and reliability.
Integrating External Data Sources
In the rapidly evolving landscape of artificial intelligence, the ability to integrate external data sources into agent workflows is crucial for building robust and intelligent solutions. This integration allows agents to access real-time information, enrich their decision-making capabilities, and adapt to dynamic environments. In this section, we will explore the importance of external data sources, discuss various types of data that can be integrated, and provide practical examples of how to implement this in Python.
External data sources can include APIs, databases, web scraping, and streaming data. Each of these sources offers unique benefits and challenges. For instance, APIs provide structured data and are often easy to integrate, but they may have rate limits or require authentication. Databases can offer comprehensive datasets but may require complex queries to extract relevant information. Web scraping allows access to unstructured data on the web, but it can be brittle if website structures change. Streaming data, such as from IoT devices or social media feeds, provides real-time insights but requires handling large volumes of data efficiently.
Let’s consider a practical example where an AI agent integrates weather data from an external API to enhance its decision-making process. Suppose we are building an AI solution for an agricultural application where the agent needs to make recommendations based on current and forecasted weather conditions. We will use the OpenWeatherMap API for this purpose. First, we need to obtain an API key by signing up on their platform. Once we have the key, we can proceed with the integration.
import requests
# Function to get weather data from OpenWeatherMap API
def get_weather_data(city, api_key):
base_url = "http://api.openweathermap.org/data/2.5/weather"
params = {
'q': city,
'appid': api_key,
'units': 'metric'
}
response = requests.get(base_url, params=params)
if response.status_code == 200:
return response.json()
else:
raise Exception(f"Error fetching data: {response.status_code}")
# Example usage
api_key = 'your_api_key_here' # Replace with your actual API key
city = 'San Francisco'
weather_data = get_weather_data(city, api_key)
print(weather_data)In the code above, we define a function get_weather_data that takes a city name and an API key as inputs. It constructs a request to the OpenWeatherMap API, retrieves the weather data in JSON format, and returns it. This function handles potential errors by checking the response status code, which is a good practice when dealing with external APIs. Now, the AI agent can use this weather data to make informed decisions, such as advising farmers on the best times for planting or harvesting.
Integrating external data sources is not limited to APIs. For example, if our AI solution needs to analyze historical weather patterns, we might connect to a database containing such data. This involves using database connectors and executing SQL queries to fetch the required information. Python’s sqlite3 library is a simple way to interact with SQLite databases. Let’s see how this can be implemented.
import sqlite3
# Function to retrieve historical weather data from an SQLite database
def get_historical_weather_data(city):
conn = sqlite3.connect('weather_data.db')
cursor = conn.cursor()
query = "SELECT date, temperature, humidity FROM weather WHERE city = ?"
cursor.execute(query, (city,))
results = cursor.fetchall()
conn.close()
return results
# Example usage
city = 'San Francisco'
historical_data = get_historical_weather_data(city)
for record in historical_data:
print(record)In this example, we connect to an SQLite database named weather_data.db and execute a SQL query to fetch historical weather data for a specified city. The get_historical_weather_data function returns a list of tuples, each containing a date, temperature, and humidity. This data can be used by the AI agent to analyze trends and improve its forecasting models. By combining real-time data from APIs and historical data from databases, agents can develop a comprehensive understanding of their operating environment, leading to more accurate and strategic decision-making.
Error Handling and Recovery Strategies
In the realm of building strategic AI solutions, error handling and recovery strategies are critical components that ensure the robustness and reliability of multi-step reasoning processes. When developing agent workflows, it’s essential to anticipate potential errors and design systems that can gracefully handle these errors without disrupting the entire workflow. This section will explore the principles of effective error handling and recovery strategies, providing insights and practical examples to guide you in implementing these techniques.
Error handling in AI workflows involves identifying points of failure, defining the types of errors that may occur, and determining appropriate responses for each error type. Common errors in multi-step reasoning processes include data retrieval failures, computational errors, and integration issues with external systems. By implementing structured error handling, you can ensure that your AI solutions are resilient and can provide meaningful feedback when things go wrong.
class DataRetrievalError(Exception):
pass
class ComputationError(Exception):
pass
class IntegrationError(Exception):
pass
# Example function demonstrating error handling in a multi-step reasoning process
def process_data(data_source):
try:
data = retrieve_data(data_source)
except Exception as e:
raise DataRetrievalError(f"Failed to retrieve data from {data_source}: {e}")
try:
result = perform_computation(data)
except Exception as e:
raise ComputationError(f"Error during computation: {e}")
try:
integrate_results(result)
except Exception as e:
raise IntegrationError(f"Failed to integrate results: {e}")
return resultIn the example above, custom exception classes are defined for different types of errors, allowing for specific error handling strategies. This approach provides clarity and enables more precise recovery actions depending on the error type. For instance, if a DataRetrievalError is raised, the system might attempt to access a backup data source or notify an administrator to check the data source’s availability.
Recovery strategies are as crucial as error detection. They involve actions taken to restore the workflow to a functional state after an error occurs. Depending on the error’s nature, recovery strategies can range from retrying operations, using default values, or even rolling back to previous states. Implementing retry mechanisms with exponential backoff can be particularly effective for transient errors, such as temporary network issues.
import time
import random
# Retry decorator with exponential backoff
def retry_with_backoff(max_attempts=3, initial_delay=1, backoff_factor=2):
def decorator(func):
def wrapper(*args, **kwargs):
delay = initial_delay
for attempt in range(max_attempts):
try:
return func(*args, **kwargs)
except Exception as e:
print(f"Attempt {attempt + 1} failed: {e}")
if attempt < max_attempts - 1:
time.sleep(delay)
delay *= backoff_factor
else:
raise
return wrapper
return decorator
@retry_with_backoff(max_attempts=5)
def unreliable_operation():
if random.choice([True, False]):
raise Exception("Random failure occurred")
return "Success"
try:
result = unreliable_operation()
print(result)
except Exception as e:
print(f"Operation failed after retries: {e}")The retry_with_backoff decorator in this code snippet exemplifies a recovery strategy that attempts to mitigate transient errors by retrying the operation with an increasing delay between attempts. This method reduces the likelihood of overwhelming a resource or encountering the same transient issue repeatedly. By incorporating such strategies, AI solutions can maintain their functionality and provide a more robust user experience even in the face of unexpected challenges.
Ultimately, effective error handling and recovery strategies in multi-step reasoning workflows not only improve the reliability and robustness of AI systems but also enhance user trust and satisfaction. By anticipating potential failures and designing systems capable of recovering from them, developers can create AI solutions that are both adaptive and resilient, ensuring they deliver consistent value even in dynamic and unpredictable environments.
Testing and Iterating Agent Workflows
Testing and iterating agent workflows are critical steps in developing robust AI solutions. These processes ensure that the system can handle real-world complexities and perform as expected across various scenarios. Given the dynamic nature of AI systems, especially those involving multi-step reasoning, continuous testing and iteration are essential for maintaining system accuracy and reliability.
To start, testing agent workflows involves validating each step of the reasoning process. This means examining how the agent processes inputs, transitions between states, and produces outputs. Testing should cover a range of scenarios, from normal operation to edge cases, to uncover potential flaws or inefficiencies. For example, if an agent is designed to recommend products based on user preferences, tests should include scenarios where user data is incomplete or contradictory.
# Example of a simple test case for a product recommendation agent
def test_recommendation_system(agent, user_data, expected_output):
"""
Test the recommendation system with given user data.
:param agent: The recommendation agent
:param user_data: Dictionary containing user preferences
:param expected_output: Expected list of recommended products
:return: Boolean indicating if the test passed
"""
try:
output = agent.recommend(user_data)
assert output == expected_output, f"Expected {expected_output}, got {output}"
return True
except Exception as e:
print(f"Test failed: {e}")
return False
# Example usage
user_data = {"preferences": ["electronics", "books"], "budget": 100}
expected_output = ["Smartphone", "E-reader"]
# Assuming 'agent' is an instance of the recommendation agent
# test_recommendation_system(agent, user_data, expected_output)Iteration in agent workflows involves refining the system based on test results and feedback. This process can include adjusting algorithms, modifying data processing steps, or reconfiguring decision-making logic. Iteration is not a one-time task but an ongoing cycle of improvement. For instance, if the recommendation agent frequently fails to suggest appropriate products for users with niche interests, the algorithm might need adjustments to better handle specialized data.
A critical part of this iterative process is incorporating feedback loops. Feedback can come from various sources, such as user interactions, system logs, or performance metrics. By analyzing this feedback, developers can identify patterns or recurring issues, which can then guide further refinements. For example, if logs show that the agent struggles with processing large datasets, developers might optimize the data handling processes or increase computational resources.
# Example of an iterative improvement process using feedback
def improve_agent(agent, feedback_data):
"""
Improve the agent based on feedback data.
:param agent: The AI agent to be improved
:param feedback_data: Data collected from previous iterations
"""
# Analyze feedback data
common_issues = analyze_feedback(feedback_data)
# Apply improvements based on identified issues
if 'slow_response' in common_issues:
agent.optimize_performance()
if 'inaccurate_recommendations' in common_issues:
agent.refine_algorithm()
# Example usage
# feedback_data = collect_feedback()
# improve_agent(agent, feedback_data)In conclusion, testing and iterating agent workflows are indispensable for developing effective AI solutions. By rigorously testing each component and iteratively refining the system based on feedback, developers can build agents that are not only accurate but also resilient to the complexities of real-world applications. This process is iterative and continuous, reflecting the evolving nature of both AI technology and user expectations.
Case Studies: Successful Agent Deployments
In this section, we will explore several case studies that highlight successful deployments of agent workflows designed for multi-step reasoning. These examples will illustrate how strategic AI solutions can be effectively implemented across different industries, showcasing the versatility and potential of agent-based systems. By examining these real-world applications, we aim to provide insights into the practical considerations and challenges encountered during the deployment of such systems.
Case Study 1: Customer Support Chatbots
One of the most prevalent applications of agent workflows is in the realm of customer service, where chatbots are used to handle customer inquiries. These chatbots leverage multi-step reasoning to understand and respond to complex queries. For instance, a customer support chatbot for an e-commerce platform might need to guide a user through the process of returning a product. This involves understanding the user’s initial request, retrieving the order details, and then providing specific instructions based on the user’s location and the product’s return policy.
class CustomerSupportAgent:
def __init__(self, order_database):
self.order_database = order_database
def handle_request(self, user_input):
# Step 1: Parse user input to identify intent
intent = self.identify_intent(user_input)
# Step 2: Retrieve order details if necessary
if intent == 'return_product':
order_details = self.retrieve_order_details(user_input)
# Step 3: Provide return instructions
return self.provide_return_instructions(order_details)
else:
return 'I can help with returns, order status, and more!'
def identify_intent(self, user_input):
# Simplified intent identification
if 'return' in user_input.lower():
return 'return_product'
return 'unknown'
def retrieve_order_details(self, user_input):
# Mock function to simulate order detail retrieval
return {'order_id': 1234, 'product': 'Wireless Earbuds', 'location': 'NYC'}
def provide_return_instructions(self, order_details):
return f"To return your {order_details['product']}, please visit our NYC store or mail it back."
# Example usage
agent = CustomerSupportAgent(order_database={})
response = agent.handle_request("I want to return my earbuds.")
print(response) # Output: To return your Wireless Earbuds, please visit our NYC store or mail it back.Case Study 2: Autonomous Financial Advisors
Another compelling example of agent workflows is in the financial sector, where autonomous financial advisors use multi-step reasoning to provide investment advice. These systems analyze a client’s financial data, assess risk appetite, and suggest a diversified portfolio. The process involves multiple stages, including data collection, risk assessment, and portfolio recommendation, each requiring careful reasoning and decision-making.
class FinancialAdvisorAgent:
def __init__(self, market_data):
self.market_data = market_data
def advise(self, client_profile):
# Step 1: Assess risk appetite
risk_level = self.assess_risk(client_profile)
# Step 2: Analyze market trends
trends = self.analyze_market_trends()
# Step 3: Recommend portfolio
return self.recommend_portfolio(risk_level, trends)
def assess_risk(self, client_profile):
# Simplified risk assessment
return 'high' if client_profile['age'] < 35 else 'low'
def analyze_market_trends(self):
# Mock function to simulate market trend analysis
return {'stocks': 'bullish', 'bonds': 'stable'}
def recommend_portfolio(self, risk_level, trends):
if risk_level == 'high':
return 'Invest 70% in stocks and 30% in bonds.'
else:
return 'Invest 40% in stocks and 60% in bonds.'
# Example usage
advisor = FinancialAdvisorAgent(market_data={})
client_profile = {'age': 30, 'income': 70000}
advice = advisor.advise(client_profile)
print(advice) # Output: Invest 70% in stocks and 30% in bonds.Case Study 3: Healthcare Diagnostic Assistants
In healthcare, diagnostic assistant agents are increasingly used to support medical professionals by providing preliminary diagnostics based on patient symptoms. These agents employ multi-step reasoning to evaluate symptoms, check against medical databases, and suggest potential conditions. This not only aids in faster diagnosis but also helps in reducing the cognitive load on healthcare providers.
class DiagnosticAgent:
def __init__(self, medical_database):
self.medical_database = medical_database
def diagnose(self, symptoms):
# Step 1: Match symptoms with conditions
possible_conditions = self.match_symptoms(symptoms)
# Step 2: Rank conditions based on probability
ranked_conditions = self.rank_conditions(possible_conditions)
# Step 3: Suggest top condition
return ranked_conditions[0] if ranked_conditions else 'No diagnosis available.'
def match_symptoms(self, symptoms):
# Mock function to simulate symptom matching
return ['Common Cold', 'Flu'] if 'cough' in symptoms else []
def rank_conditions(self, conditions):
# Simplified ranking based on predefined logic
return sorted(conditions, key=lambda x: x == 'Flu', reverse=True)
# Example usage
diagnostic_agent = DiagnosticAgent(medical_database={})
symptoms = ['cough', 'fever']
diagnosis = diagnostic_agent.diagnose(symptoms)
print(diagnosis) # Output: FluThese case studies demonstrate the diverse applications of agent workflows in solving complex problems across various domains. In each scenario, the agents follow a structured process to achieve their goals, showcasing the importance of designing effective multi-step reasoning workflows. As you consider deploying your own strategic AI solutions, these examples serve as a foundation for understanding the key components and considerations involved in successful agent deployments.