6 Large Language Models

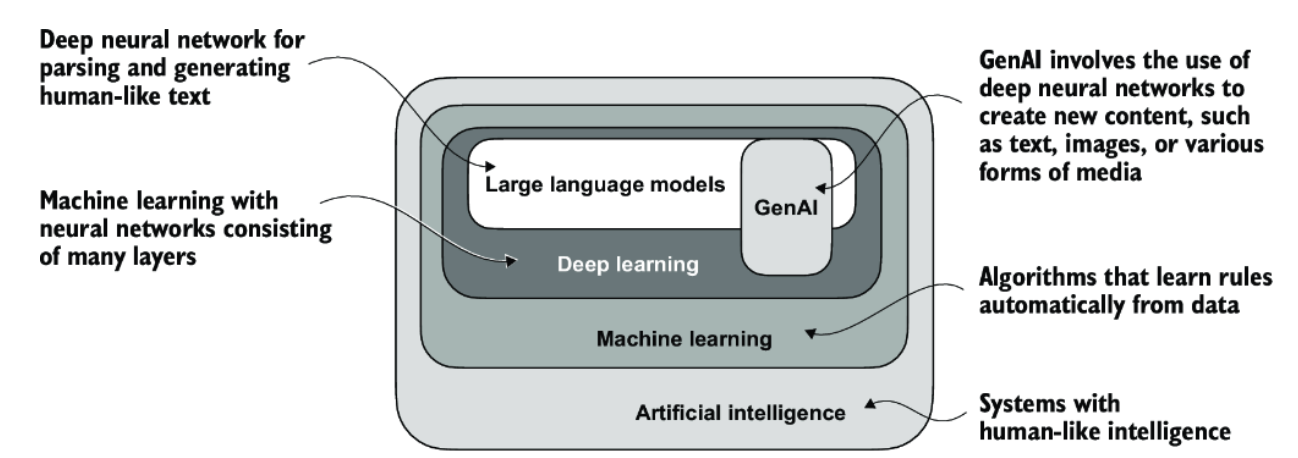
6.1 Glossary
6.2 Words represented as numbers
2000 - Bag of Words 2013 - Word2Vec 2017 - Attention
6.3 Key Terms
Vector:
Matrix:
Dimension:
Character:
Text string: A sequence of characters forming natural language (e.g., “The quick brown fox”).
Corpus:
Tokenizer: An algorithm that splits a text string into ‘tokens.’
Tokenization: The process of using a tokenizer to split a text string into smaller units (tokens), typically words or subword fragments.
Token: A single unit resulting from tokenization, often a word or part of a word.
Vocabulary: A fixed list of all known tokens. Each token is mapped to a unique integer (token ID).
Token ID: A unique integer assigned to a token by a tokenizer. In Word2Vec, token IDs are not used or exposed. Instead, the token is represented directly as a character string.
Embedding Model: An embedding model is a model that transforms each input token—either a character string or a token ID—into a vector of real numbers. The elements of this vector capture aspects of the token’s semantic meaning, syntactic role, and relationships to other tokens in the corpus. These vector representations can then be used as input to downstream machine learning models for tasks such as classification, clustering, translation, or text generation.
- Word2Vec – A neural model that creates static word embeddings based on word co-occurrence. Pre-trained versions (such as the Google News model) are available off the shelf using the gensim library.
Embedding: A vector that represents a token’s learned meaning and context. GPT-2 era models typically use embedding sizes of 768 dimensions, while GPT-3 models use much larger embeddings—up to 12,288 dimensions for the largest model variants (source: Build LLMs from Scratch). Embeddings can be derived from off-the-shelf models like Word2Vec, but modern large language models (LLMs) learn these embeddings during training as part of an integrated process, rather than relying on pre-trained static embeddings. Embeddings can also be created for larger units such as sentences, paragraphs, or entire documents.
Embedding Matrix: A matrix in which each row contains the embedding vector for a particular token. It functions as a lookup table to retrieve the embedding for a given token (Word2Vec) or in modern LLMs a token ID. The embedding matrix is a core component of what is commonly referred to as the embedding layer in neural network models.
Embedding layer: A layer in a neural network that maps discrete input tokens—typically represented by token IDs—into continuous vector representations by retrieving rows from an embedding matrix. During training, this matrix is randomly initialized and then updated via backpropagation to learn useful representations. After training, the embedding layer functions as a fixed lookup table that outputs meaningful vectors for each token.
Rotary Embedding (RoPE): Positial embedding information is added at the self embedding layer.
Mixture of Experts: variant of tranformation model.
- Router
Generative vs Representation Models: “Representation models are LLMs that do not generate text but are commonly used for task-specific use cases, like classification, whereas generation models are LLMs that generate text, like GPT models. Although generative models are typically the first thing that comes to mind when thinking about LLMs, there is still much use for representation models.” (Alammar and Grootendorst (2024))
“In other words, the embedding layer is essentially a lookup operation that retrieves rows from the embedding layer’s weight matrix via a token ID.”
Tensor:
Shape: The dimensions of a tensor — specifically, the number of elements along each axis.
| Tensor Type | Rank | Example Shape | Example Description |
|---|---|---|---|
| Scalar | 0 | () |
A single number (e.g., 5) |
| Vector | 1 | (3,) |
A list of numbers (e.g., [5, 2, 7]) |
| Matrix | 2 | (3, 4) |
A 2D table (e.g., 3 rows × 4 columns) |
| 3D Tensor | 3 | (10, 3, 4) |
A stack of 10 matrices, each 3×4 |
| n-D Tensor | n | (d1, d2, ..., dn) |
Any n-dimensional array |
Backpropogation: The algorithm used to train neural networks by adjusting the model’s weights to reduce error.
Feedforward: The process of passing input data through a neural network to produce an output. Data flows forward from the input layer through one or more hidden layers to the output layer. At each layer, neurons apply a weighted sum and an activation function (e.g., ReLU, GELU) to produce their outputs. No learning or weight updates happen during this step — it’s just computing the prediction. This is how the model computes predictions, whether during training or inference.
Logits: “The model outputs, which are commonly referred to as logits”
Dense Vector: A vector in which most or all elements are non-zero and explicitly stored. In NLP, dense vectors (such as embeddings) represent features in a compact, continuous space and are learned during model training.
Input → Feedforward → Prediction ↓ Loss Computation ↓ Backpropagation (Gradients) ↓ Optimization (Weight Update) ↓ Next iteration
Stochastic Gradient Descent:
Batched Matrix Multiplication:
– Transformer: Does not use an RRN.
BERT: Encoder only. Good at language translation but not other tasks.
Masked Language Modeling: Mask some of the input words and predict them.
Generative Models: Decoder only models.
GPT: Generative Pretrained Transformer.
Context Length
GPU:
Scaled dot-product attention:
Context vectors:
Weight Matrix: Generic term that can refer to any trainable matrix where each element is a weight that gets updated during training.
During training, each batch of data goes through a feedforward pass to compute a prediction, then a backpropagation pass to update the model’s weights.
Excerpt From Build a Large Language Model (From Scratch) Sebastian Raschka This material may be protected by copyright.
Input embedding: The final vector input to the model for each token, typically formed by summing token embeddings with positional (and optional segment) embeddings.
Detokenization - The process of reconstructing a human-readable string from tokens.
Embeddings can be combined
- Word, Sentence, Document
Vocabulary (Bag of Words): distint list of tokens
Encoder - The goal of an encoder is to convert input data—such as text—into a numerical representation (embedding) that captures its meaning, structure, and context. In the context of language models, encoders are designed to understand and represent the input text in a way that can be used for downstream tasks like classification, translation, or generation. Mathematically an encoder is often a recurrent neural network.
Decoder - Goals is to generate language. Takes as inputs, embeddings, and then maps those embeddings to new embeddings, i.e. lanauge translation.
Bag-of-Words
Word2Vec - A pre-trained model that creates word embeddings. Available off the shelf.
- Vector Embeddings - Captures the meaning of words. Each Vector (word) embedding represents an aspect of the relationship a given word has with many other words. Each entry in a vector embedding is a number that measures something about the relationship between a word and the word the vector represents. Each vector embedding can have 1024 entries or more. The values of each entry are derived from the perameters of a neural network.
“The main idea behind Word2Vec is that words that appear in similar contexts tend to have similar meanings.” Excerpt From Build a Large Language Model (From Scratch) Sebastian Raschka This material may be protected by copyright.
- Static embeddings. e.g. bank has the same embedding regardless if the sentence is “bank of a river” or “going to the bank”
Neural network
- Recurrent Neural Networks - precludes parallelization. This is why the tranformer architecture was so powerful as it allows parallelization.
Parameters: “In the context of deep learning and LLMs like GPT, the term “parameters” refers to the trainable weights of the model. ” “These weights are essentially the internal variables of the model that are adjusted and optimized during the training process to minimize a specific loss function.”
Autoregressive - decoders produce one new token at a time, taking the all previous tokens as input to predict the next best token.
Projection Matrices
- Query Projection
- Key Projection
- Value Projection
Multi query attention
Grouped query attention
Feedforward Neural Network
Self-attention (encoder???). works by seeing how similar each word is to all of the words in the sentence, including it self. Calculates the simliarity between every every word in the sentence.
- Takes the longest and most computation. W
- Attention head
Attention - First introduced in 2014. got big in 2017. Attention allows a model to focus on parts of the input that are relevant to on another. Attend to one another and amplify their signal. Attention selectively determines which words are most important in a given sentence.
Attention: “weights”, “attends to”, “pays attention to” each input tokens embedding indepentently based on where it is in the input and output. “A way for the model to”pay attention” to different input tokens when processing each token, so it can focus more on the relevant words, even if they’re far away in the sequence.”
6.4 Scaled Dot-Product Attention
The core equation for attention used in Transformers is:
\[ \text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^\top}{\sqrt{d_k}} \right)V \]
6.4.1 Explanation of Terms
- \(Q\): Query matrix (sequence length × \(d_k\))
- \(K\): Key matrix (sequence length × \(d_k\))
- \(V\): Value matrix (sequence length × \(d_v\))
- \(d_k\): Dimensionality of the key vectors (used for scaling)
6.4.2 Intuition
- Compute the dot product between \(Q\) and \(K\): \(QK^\top\)
- Scale by \(\sqrt{d_k}\) to control the magnitude
- Apply softmax to get attention weights
- Multiply by \(V\) to get the final weighted output
The Terms Query, Key, Value come from database terminology (Starmer (2025))
Masked self-attention (decoder) - removed upper diagonal. Also called Causal self-attention
Causal self-attention:
Multi-head attention:
Hidden states of a word can be passed to a decoder. Hidden states are a vector representation.
BERT 2018 - Encoder only architecture. Forms the basis for most of the embedding models that are popular today for RAG.
CLS token
Masked lanaguage modeling. Predict the masked words. Pre-trainiing. Fine tune for downstream tasks.
Generative models use a different architecture. Decoders only. GPT-1. Generative pretrained transformer
Context length, GPT
Each word has a static embedding from Word2Vec. These embeddings are passed to the encoder as a set. The individual embeddings are then combined into a single “context” embedding. The “context” embedding is then passed to the decoder.
Once students understand static embeddings (Word2Vec), it becomes much more intuitive to explain: “Now imagine that the same word has a different vector depending on its sentence context — that’s what GPT does.”
Word2Vec was a milestone in NLP (2013), and understanding it provides insight into how word embeddings evolved from: Bag of Words → TF-IDF → Word2Vec → GloVe → Contextual embeddings (BERT/GPT)
- Bag of Words and TF-IDF (symbolic → numeric)
- Word2Vec (static embeddings, co-occurrence-based learning)
- GloVe (matrix factorization variant)
- fastText (subword embeddings and OOV handling)
- BERT/GPT embeddings (contextual, dynamic)
- Embeddings as foundation for downstream tasks
LM Head: Token probability calculation. Probability
Decoding Strategy
- Greedy decoding: Temperature = 0
- top_p: Temperature > 0
Temperature Parameter:
Reinforcement learning from human feedback (RLHF)
Relevance scoring:
Projection:
Byte Pair Encoding (BPE): “Builds its vocabulary by iteratively merging frequent characters into subwords and frequent subwords into words. For example, BPE starts with adding all individual single characters to its vocabulary (“a,” “b,” etc.). In the next stage, it merges character combinations that frequently occur together into subwords. For example, “d” and “e” may be merged into the subword “de,” which is common in many English words like “define,” “depend,” “made,” and “hidden.” The merges are determined by a frequency cutoff.”
Layer normalization: “The main idea behind layer normalization is to adjust the activations (outputs) of a neural network layer to have a mean of 0 and a variance of 1, also known as unit variance. This adjustment speeds up the convergence to effective weights and ensures consistent, reliable training. In GPT-2 and modern transformer architectures, layer normalization is typically applied before and after the multi-head attention module”
Batch normalization: “normalizes across the batch dimension vs layer normalization which normalizes across the feature dimension”
Shortcut connections, also known as skip or residual connections - “a shortcut connection creates an alternative, shorter path for the gradient to flow through the network by skipping one or more layers, which is achieved by adding the output of one layer to the output of a later” “Shortcut connections are a core building block of very large models such as LLMs, and they will help facilitate more effective training by ensuring consistent gradient flow across layers”
Vanishing gradient: “problem refers to the issue where gradients (which guide weight updates during training) become progressively smaller as they propagate backward through the layers, making it difficult to effectively train earlier layers.”
Loss Function:
Transformer Block : “combines multi-head attention, layer normalization, dropout, feed forward layers, and GELU activations” “outputs of the transformer block are vectors of the same dimension as the input, which can then be fed into subsequent layers in an LLM.” “a core structural component of GPT models, combining masked multi-head attention modules with fully connected feed forward networks that use the GELU activation function.”
Weight Tying:
Softmax:
Training example:
Batch:
Outputs of the layer:
Dropout: “ there are three distinct places where we used dropout layers: the embedding layer, shortcut layer, and multi-head attention module.”
6.5 How LLMs work
Transformers are a typer of neural network.
Unlike earlier neural networks (like RNNs or CNNs), Transformers rely entirely on attention mechanisms and avoid recurrence, allowing for better parallelization and performance on long sequences.
Transformers have three components: 1. Word Embedding 2. Positional Encoding - keeps track of word order 3. Attention
Transformer LLMs generate their output one token at a time.
Transformer has three major components: 1. Tokenizer 2. Tranformer Block - Most of them computation happens here. This is where the main neural network models live. GPT-3.5 had about 96 transformer blocks. - self attention layer - Relevance scoring - Combining information - Feed forward neural network 3. LM Head - Also a neural network. - Only recieves the final token from the input sequence and then predicts the next word.
Transformers process their input tokens in parallel. If an input prompt has 16,000 tokens, the model will process this many tokens in parallel.
KV Caching.
Time to first token. How
6.6 Hyperparameters
6.6.1 Model Architecture
| Hyperparameter | Description | Typical Values / Notes |
|---|---|---|
vocab_size |
Number of unique tokens in the vocabulary | 30,000 – 100,000+ |
max_position_embeddings |
Maximum input sequence length | 128 – 2048+ |
d_model |
Embedding & hidden size | 128 – 12,288 (GPT-3 uses 12,288) |
num_layers / n_layers |
Number of Transformer blocks | 2 – 96+ |
num_heads / n_heads |
Number of attention heads per block | Must divide evenly into d_model |
d_ff / ffn_dim |
Feedforward network hidden size | Typically 4 × d_model |
dropout_rate |
Dropout probability | 0.0 – 0.3 |
activation_function |
Activation used in FFN | "relu", "gelu", "silu" |
layer_norm_eps |
Small constant for LayerNorm stability | 1e-12 – 1e-5 |
6.6.2 Attention Mechanism
| Hyperparameter | Description | Typical Values / Notes |
|---|---|---|
attention_dropout |
Dropout on attention weights | Helps regularize training |
use_bias |
Whether projection layers have bias | True / False |
use_scaled_dot_product |
Use scaled dot-product attention | Usually True |
relative_position_encoding |
Use relative instead of absolute positions | Used in Transformer-XL, T5, etc. |
6.6.3 Training Configuration
| Hyperparameter | Description | Typical Values / Notes |
|---|---|---|
learning_rate |
Initial learning rate | 1e-5 – 1e-3 |
batch_size |
Examples per batch | 8 – 2048 |
num_epochs |
Number of passes through training data | 3 – 50+ |
weight_decay |
L2 regularization coefficient | 0.0 – 0.1 |
gradient_clip_norm |
Clip gradients to this norm | 0.5 – 1.0 |
optimizer |
Optimization algorithm | Adam, AdamW, AdaFactor, etc. |
learning_rate_scheduler |
Adjust learning rate over time | linear, cosine, constant, etc. |
warmup_steps |
Steps before learning rate decay | 500 – 10,000+ |
6.6.4 Tokenizer & Embeddings
| Hyperparameter | Description | Notes |
|---|---|---|
tokenizer_type |
Tokenization algorithm | BPE, WordPiece, SentencePiece |
share_embeddings |
Share encoder & decoder embeddings | Used in T5 |
6.6.5 Decoder-Specific
| Hyperparameter | Description | Notes |
|---|---|---|
use_encoder_decoder |
Whether model includes a decoder | True for T5, translation, etc. |
decoder_num_layers |
Number of decoder layers | Can differ from encoder |
cross_attention |
Enables decoder to attend to encoder output | Required in encoder-decoder models |
6.7 Understanding Attention
By computing an attention weight, you are asking the question:
How similar is a given token to every other token in the input sequence as measured by the dot product between each pair of embeddings? We then normalized this set of weights using the softmax function which ensure that all the weights sum to 1. for a given token.