import os
import time
import pandas as pd
from openai import OpenAI
# --- Config ---
INPUT_CSV = "input.csv"
OUTPUT_CSV = "output.csv"
MODEL = "gpt-4o-mini"
SYSTEM_PROMPT = "You are a helpful assistant."
API_KEY = os.getenv("OPENAI_API_KEY", "YOUR_OPENAI_API_KEY") # or set env var
# --- Client ---
client = OpenAI(api_key=API_KEY)
# --- Load data ---
df = pd.read_csv(INPUT_CSV)
# Ensure expected columns exist
for col in ["name", "topic", "tone"]:
if col not in df.columns:
raise ValueError(f"Missing required column: {col}")
def call_api(row, retries=3, backoff=2.0):
"""Call OpenAI once per row with simple retry/backoff."""
prompt = f"Write a {row['tone']} introduction to {row['topic']} for someone named {row['name']}."
for attempt in range(retries):
try:
resp = client.chat.completions.create(
model=MODEL,
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": prompt},
],
temperature=0.7,
)
# Newer client returns attributes, not dicts:
return resp.choices[0].message.content.strip()
except Exception as e:
if attempt == retries - 1:
return f"Error: {e}"
time.sleep(backoff ** attempt)
# --- Run generation ---
df["response"] = df.apply(call_api, axis=1)
# --- Save results ---
df.to_csv(OUTPUT_CSV, index=False)
print(f"Done. Wrote {len(df)} rows to {OUTPUT_CSV}")LLMs & Prompting
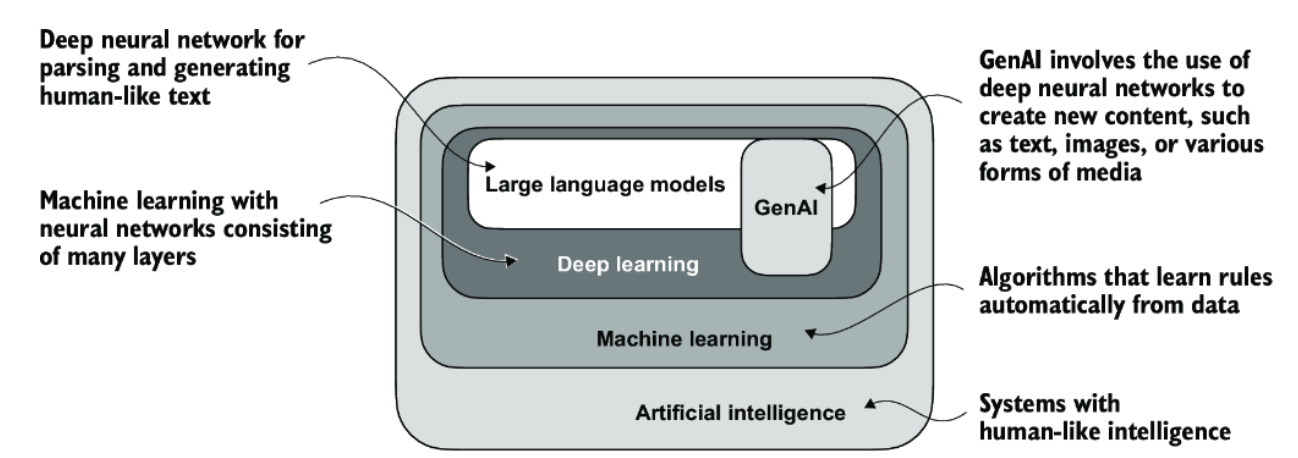
AI and Machine Learning
You first need to understand something about how this technology works, at least at a high level. Artificial Intelligence (AI) is the broad idea of creating computer systems that can perform tasks we normally associate with human intelligence, like understanding language, recognizing patterns, making decisions, and generating creative content.
Machine Learning (ML) is a subset of AI that focuses on teaching computers to learn from data instead of following hard-coded instructions. In ML, we give the computer many examples (data) and let it find the patterns on its own. The more and better-quality data it sees, the better it gets at making predictions or generating useful outputs.
Within machine learning, deep learning uses layers of artificial “neurons” to handle extremely complex patterns—this is the technology behind most modern breakthroughs, including Large Language Models (LLMs) like ChatGPT.
Even if you won’t be building models yourself, understanding these basic concepts will help you ask the right questions, spot opportunities for AI in products, and work effectively with technical teams.
Supervised Learning
The branch of machine learning that powers today’s Generative AI breakthroughs is supervised learning. A conceptual example of supervised learning is teaching someone to guess the next word in a sentence by giving them lots of examples with the right answers.
For instance, imagine we train a model on sentences like:
- The cat sat on the mat.
- She went to the store.
- I like to eat pizza.
In each case, the words before the blank are the input, and the correct missing word is the label. The model makes a guess, checks if it matches the label, and adjusts its internal weights to improve next time.
After seeing millions of examples, the model learns patterns in how words are used so it can predict the missing word—even in sentences it has never seen before.
In short: supervised learning is learning patterns from labeled examples so you can make accurate predictions on new, unseen data.
The simplest form of supervised learning is regression, where the goal is to predict a number based on input data. For example, given a set of sentences and their average reading times, a regression model could learn to predict how long it might take someone to read a new sentence. The model trains on many input–output pairs, gradually learning the relationship between the features in the input and the numeric value in the output.
While regression can be done with simple formulas, modern AI—including Large Language Models—relies on neural networks to handle far more complex patterns. Neural networks are essentially many layers of interconnected regression-like steps, stacked and tuned to capture relationships in huge datasets.
Understanding these building blocks will help you see how LLMs work under the hood, even if the scale and complexity are much greater than in basic regression.
Gradient Descent
Gradient descent is the learning process that tunes a model to make better predictions over time. Imagine you’re standing on a foggy hillside and want to get to the lowest point in the valley. You can’t see far, so you take small steps downhill in the steepest direction you can feel under your feet.
In a neural network, the “hill” is the error, how wrong the model’s predictions are. The “steps” are weight adjustments which change the models predictions. After each guess, the network measures the error, figures out which direction will reduce it the most, and then tweaks the weights slightly to move in that direction.
By repeating this process many times, the network eventually settles in a low spot where the error is as small as possible.
In short: gradient descent is the process of taking small steps to reduce errors until the model’s predictions are as accurate as it can make them.
Large Language Models and Generative AI
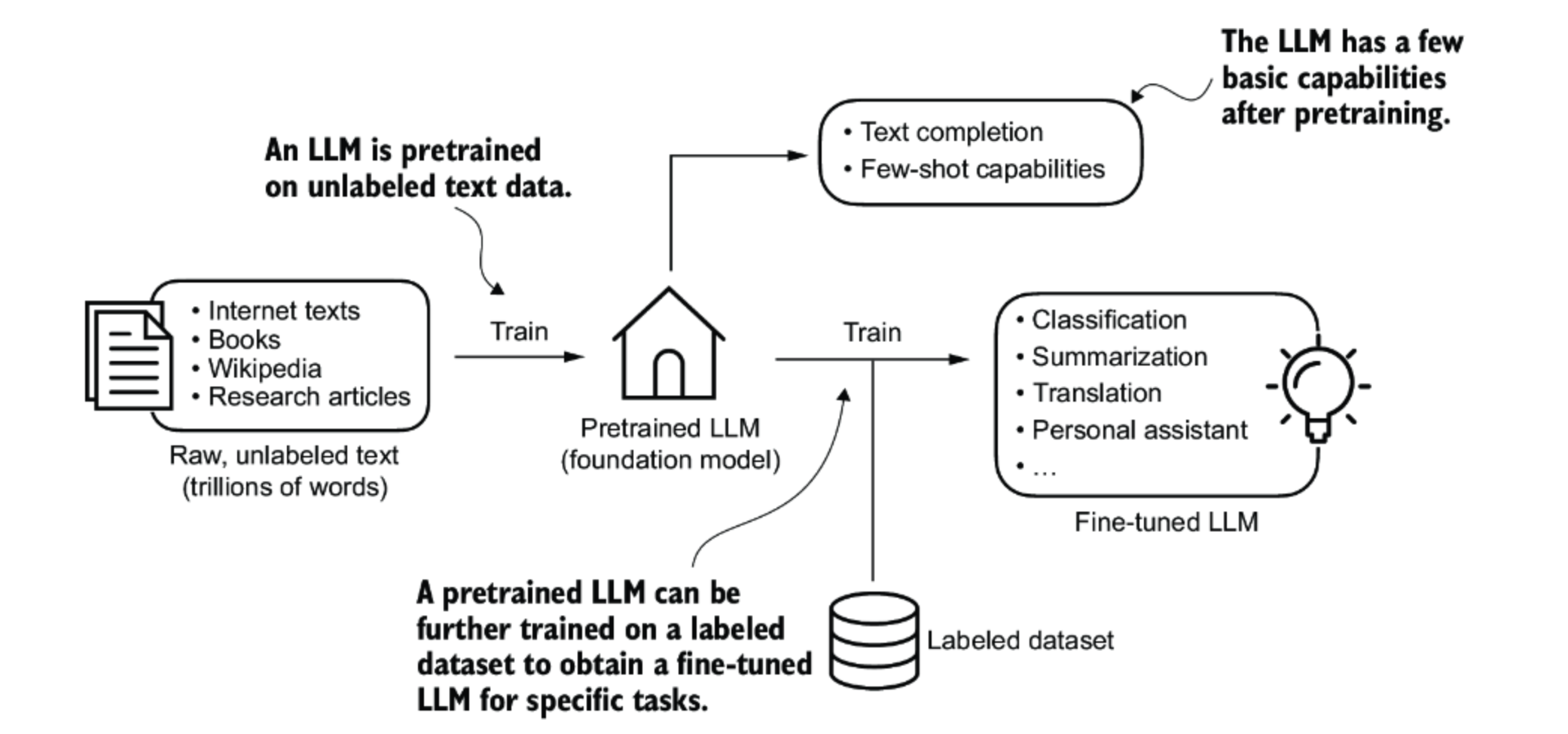
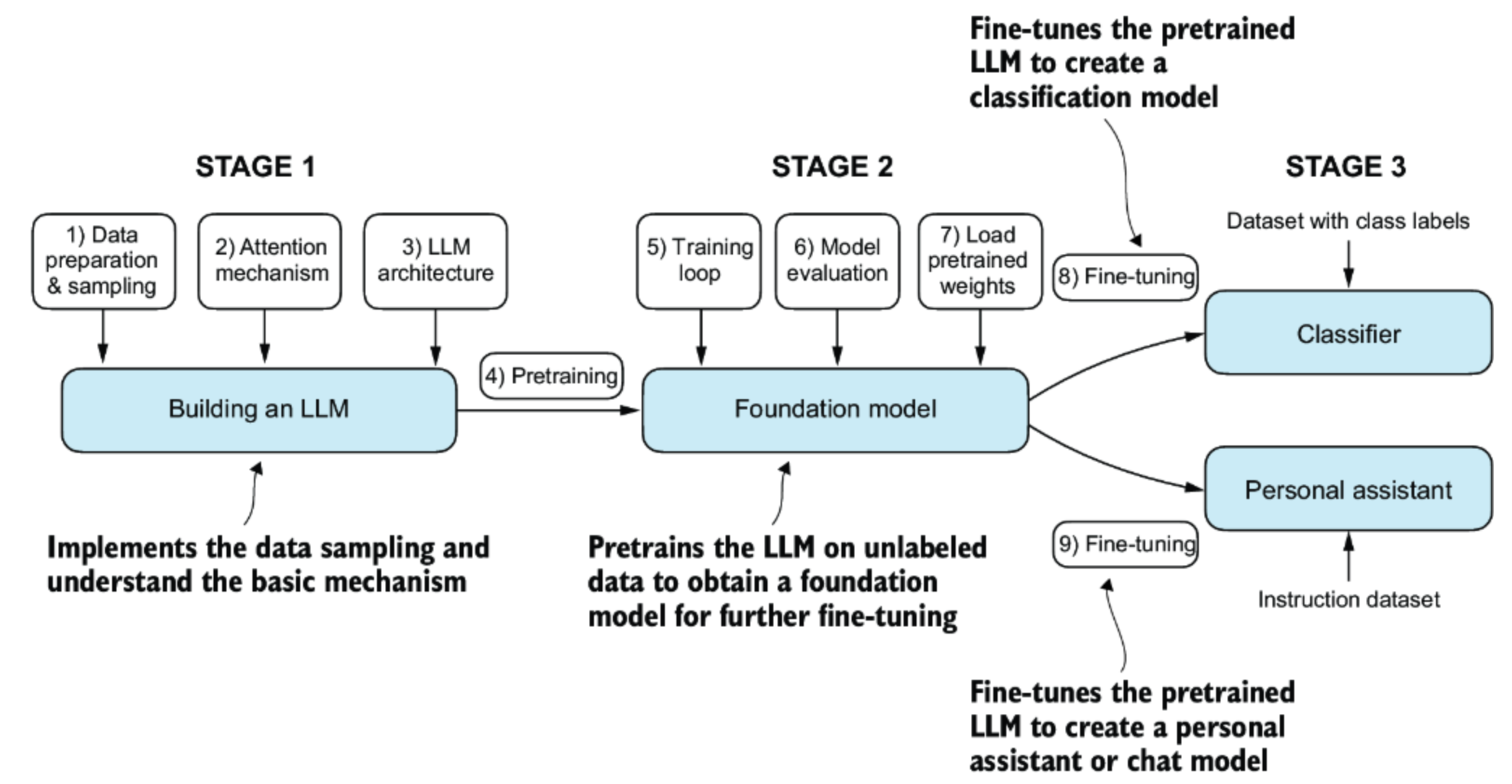
Large Language Models (LLMs) are the core technology behind much of today’s Generative AI. They are built in two main stages: pretraining and fine-tuning
1. Gathering and Processing Text Data
The process begins by collecting an enormous body of text from a variety of sources, including internet articles, books, Wikipedia, and research papers. This raw text can contain trillions of words. Before a model can use it, the text is converted into numbers through a process called tokenization. Each word or piece of a word is represented as a vector (a list of numbers) so the computer can process it mathematically.
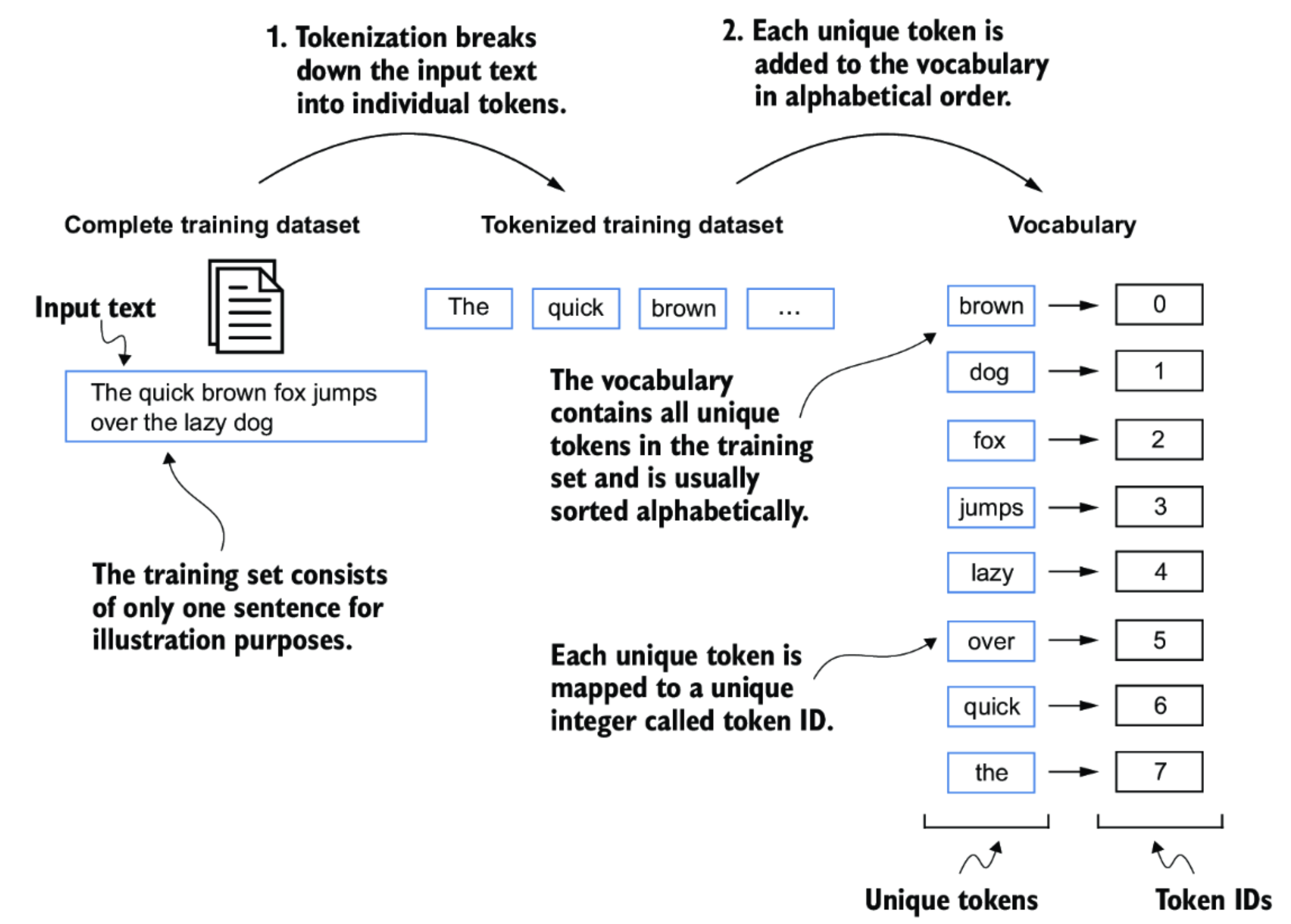
2. Pretraining the Model
Using this massive numerical dataset, the model is trained to perform one fundamental task: predicting the next word in a sequence. By doing this billions of times, it learns grammar, facts about the world, reasoning patterns, and relationships between concepts. After pretraining, the LLM becomes a foundation model with basic capabilities such as:
- Text completion – finishing a sentence or paragraph.
- Few-shot learning – adapting to new tasks with just a few examples in the prompt.
3. Fine-Tuning for Specific Tasks
Pretraining gives the model broad language skills, but it’s still general-purpose. Fine-tuning makes it specialized. In this stage, the pretrained model is trained again on a labeled dataset—data where each input has a known, correct output. This allows the LLM to excel at targeted applications such as:
- Classification – sorting emails as spam or not spam.
- Summarization – condensing long documents into key points.
- Translation – converting text between languages.
- Conversational assistance – answering questions and performing tasks as a chatbot or virtual assistant.
4. The Big Picture
- Pretraining = learning the general rules of language and knowledge.
- Fine-tuning = specializing for specific, high-performance applications.
Together, these steps create powerful AI systems capable of generating text, answering questions, and performing a wide variety of language-based tasks.
Embeddings
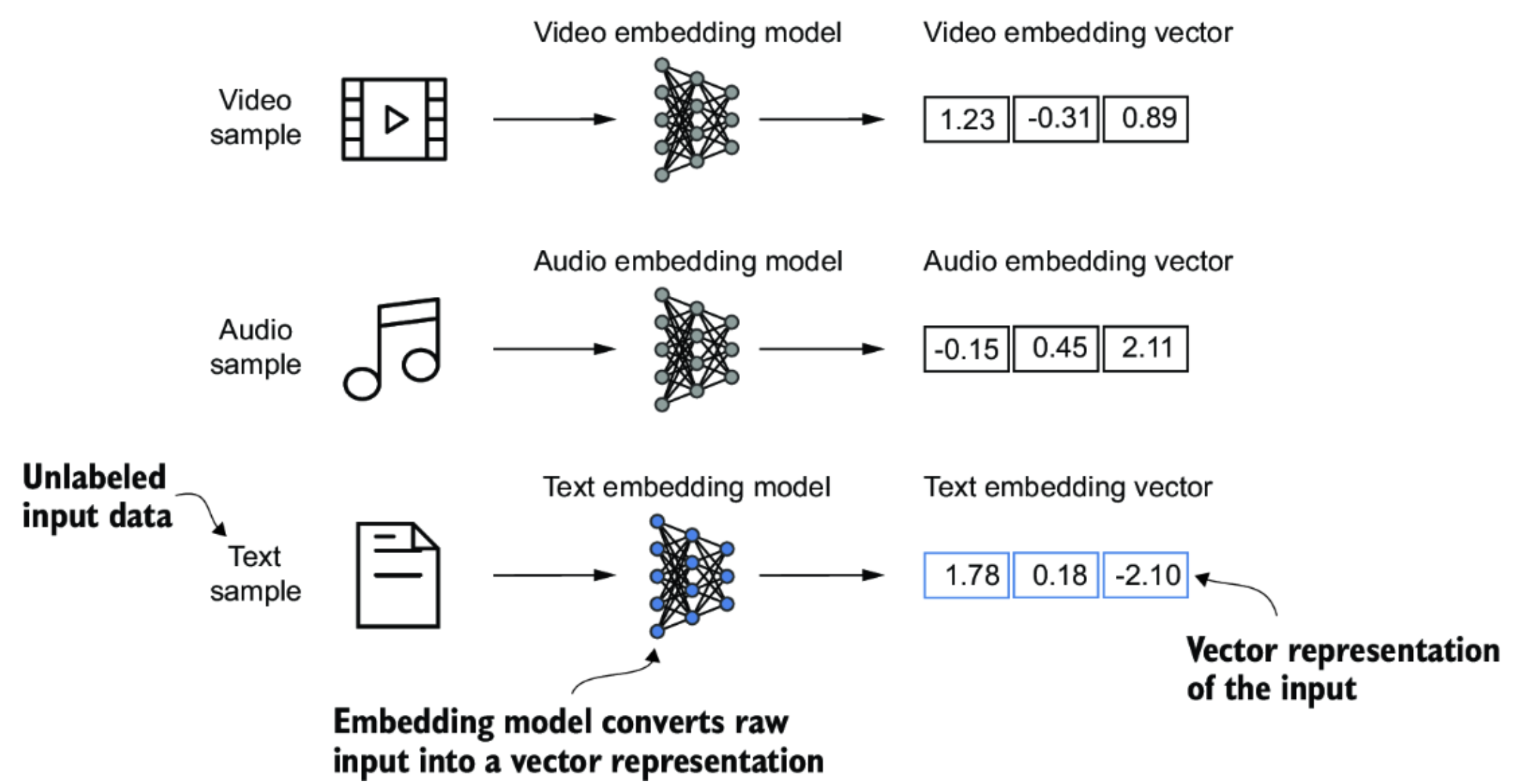
Embeddings are a way to turn different kinds of information—like text, audio, or video—into numbers so a computer can work with them.
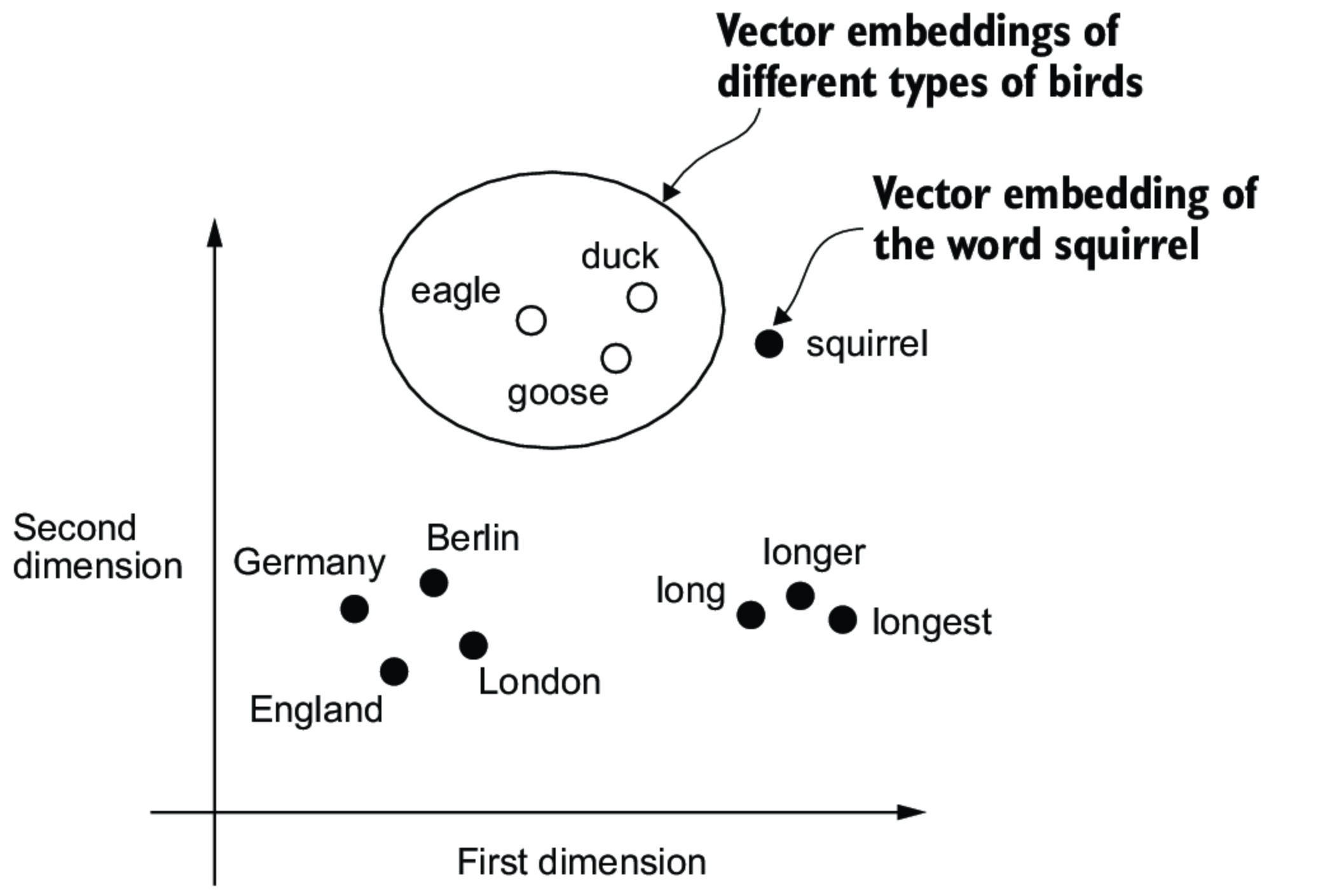
An embedding model is a deep neural network that takes raw input (words, sounds, images, etc.) and converts it into a list of numbers that captures the meaning or important features of the input (i.e. a vector). Two inputs with similar meanings will have vectors that are close to each other, even if the exact words, sounds, or images are different.
Embeddings are like coordinates on a map of word meanings. They let computers compare, search, and work with language in a numerical and mathematical way.
Neural Networks
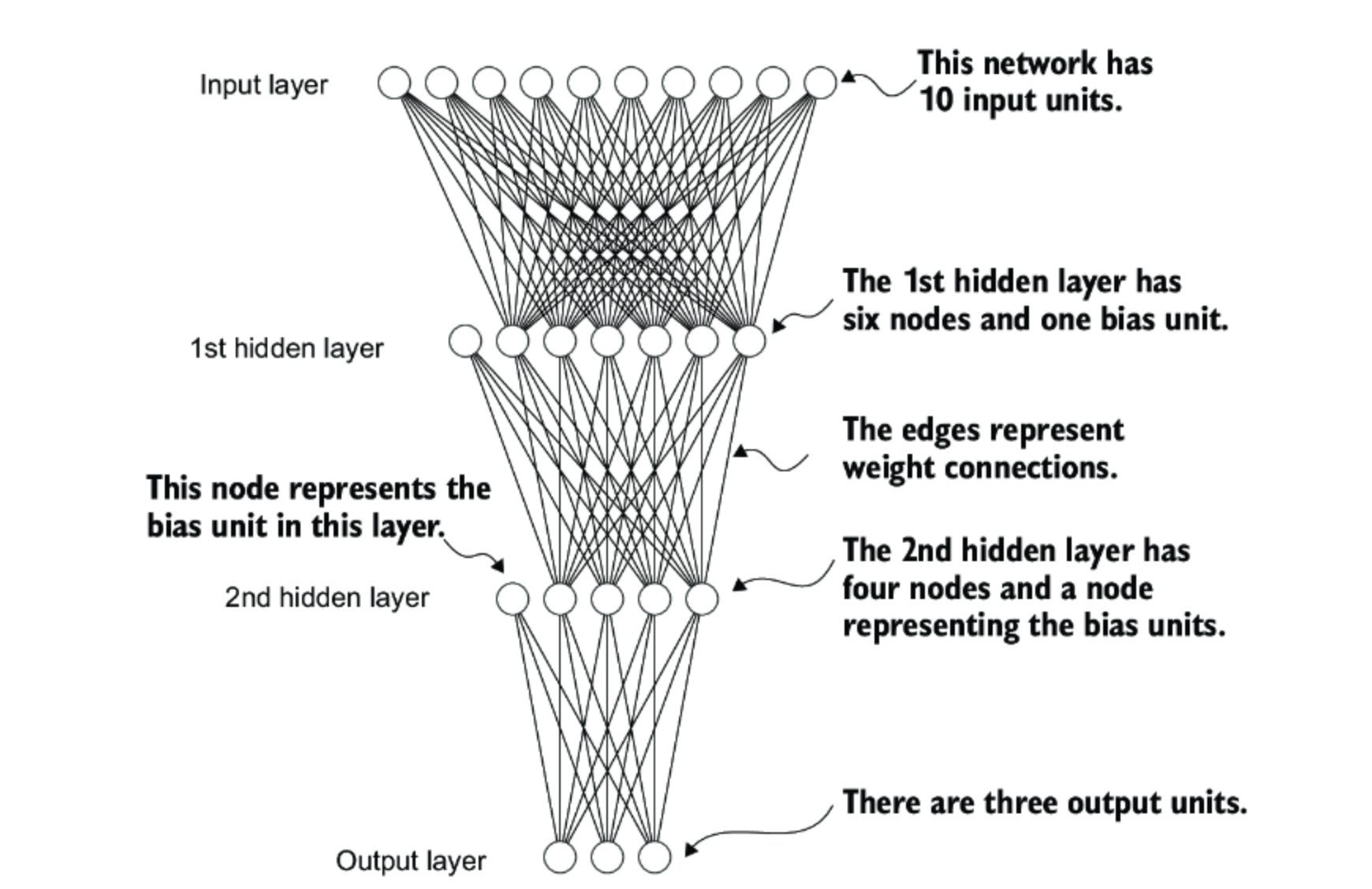
A neural network is a way for a computer to learn patterns and make predictions, inspired loosely by how our brains work. It’s built from layers of tiny “decision-makers” called neurons. Each connection between neurons has a weight, which is just a number that tells the network how important that connection is.
Numerical representations of words (vectors) flow layer by layer through the network. At each layer, a neuron takes the numbers it receives, multiplies them by its connection weights, adds them together, and applies a simple rule (called an activation function) before passing the result to the next layer. This step-by-step movement of information is called feed-forward. In the context of LLMs, once all layers have done their work, the final output numbers indicate which word is most likely to come next based on the input provided.
At first, the weights are random, so the network’s guesses for the next word are usually terrible. During training, it compares its guesses to the correct answers in the training corpus, measures how far off it was, and then adjusts the weights, analogous to turning millions (or even billions) of tiny knobs to make a slightly better guess next time. This process repeats again and again until the weights are tuned so well that the model predicts the next word correctly as often as possible.
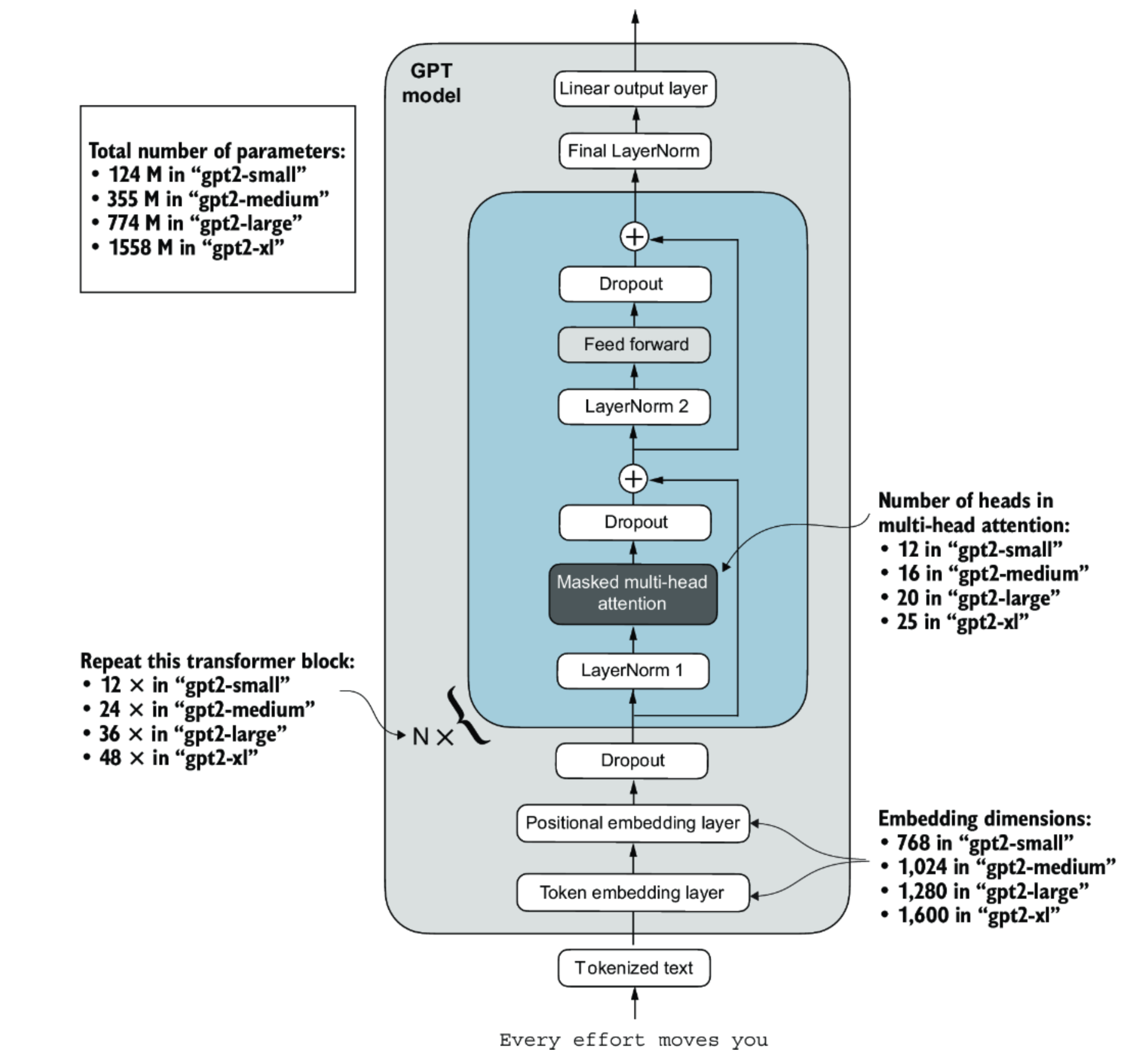
GPT Architecture
Digging into the full details of the GPT architecture is beyond the scope of this course. However, it’s useful to recognize diagrams like this, which present the high-level structure of the model. At the bottom, tokenized text (converted into numerical tokens) passes through an embedding layer that maps each token to a numerical vector. A positional embedding layer adds information about word order.
The heart of GPT is the transformer block (shaded in blue), repeated many times (e.g., 12 layers for GPT-2 Small, 48 for GPT-2 XL). Each block contains:
- Masked multi-head attention – allows the model to focus on relevant words in the input while preventing it from “seeing” future words during training.
- Feed-forward layers – process and transform the attention outputs.
- Layer normalization and dropout – improve stability and reduce overfitting.
Each layer in the GPT architecture is part of a deep neural network and performs a sequence of mathematical operations—primarily matrix multiplications and additions—that transform the input vectors into increasingly abstract representations of the text. During training, the model’s parameters (weights) are adjusted using gradient descent, an optimization process that reduces prediction errors by calculating how much each weight should change based on the difference between the model’s output and the correct answer.
After going through all the layers, the model tidies up its final internal calculations and then turns them into a list of possible next words, each with a score for how likely it is to come next. The word with the highest score is usually chosen as the model’s prediction.
Anatomy of Various Prompt Structures
Prompts come in many shapes, depending on your goals, the complexity of the task, and how much control you need over the AI’s output. Understanding the anatomy of different prompt structures helps you choose the right one for the job.
Anatomy of Various Prompt Structures
Prompts come in many shapes, depending on your goals, the complexity of the task, and how much control you need over the AI’s output. Understanding the anatomy of different prompt structures helps you choose the right one for the job.
| Prompt Type | What it is | Example | Best for |
|---|---|---|---|
| Single-Turn Prompt | A one-off instruction or question sent to the model. | Summarize this article in three bullet points. | Quick tasks where context isn’t needed beyond the immediate request. |
| Role-Based Prompt | Sets a clear role or persona for the AI to adopt. | You are an experienced product manager. Draft a launch plan for a new mobile app. | When tone, perspective, or expertise level matters. |
| Context + Instruction Prompt | Combines background information with a direct request. | Background: Our company sells eco-friendly cleaning products online. Task: Write a short ad targeting parents concerned about chemical safety. | When the model needs background to produce relevant results. |
| Few-Shot Prompt | Includes examples of desired input-output pairs to guide the model’s style or format. | Q: What is the capital of France? A: Paris Q: What is the capital of Germany? A: Berlin Q: What is the capital of Italy? A: |
Training the model in your preferred style or pattern without fine-tuning. |
| Multi-Turn Conversation | A back-and-forth exchange where previous messages build context. | User: Give me a list of U.S. national parks in the West. AI: [List] User: Now sort them by size. |
Complex tasks where you refine or expand the request over time. |
| Dynamic, Variable-Injected Prompt | A template where parts of the prompt are filled in with live or changing data. | Write a {tone} introduction to {topic} for someone named {name}. | Automation, personalization, and programmatic API workflows. |
By mixing and matching these structures, you can create prompts that are concise, rich in context, and tailored for automation and enabling far more consistent and useful AI outputs.
Programmatic and Dynamic Prompting
AI’s impact grows dramatically when you automate prompts and dynamically inject fresh data into them.
The python code chunk below illustrates how to do this.
This script reads a CSV, sends each row’s data to the OpenAI API, and saves the responses to a new CSV.
Flow:
input.csv → Pandas DataFrame → AI prompt → OpenAI API → response → output.csv
Steps
- Import libraries –
pandasfor CSV handling,openaifor API calls,timefor retries. - Config settings – file paths, model name, system prompt, API key.
- Create client –
client = OpenAI(api_key=API_KEY)to connect to OpenAI. - Load CSV –
df = pd.read_csv(INPUT_CSV)stores the spreadsheet in a DataFrame. - Check columns – ensure
name,topic, andtoneexist. - Define
call_api()– builds a dynamic prompt, sends it to the API, retries if needed. - Apply function –
df["response"] = df.apply(call_api, axis=1)runs the prompt for each row. - Save output –
df.to_csv(OUTPUT_CSV, index=False)writes results to a new file.